
- Selenium 教程
- Selenium - 首页
- Selenium - 概述
- Selenium - 组件
- Selenium - 自动化测试
- Selenium - 环境搭建
- Selenium - 远程控制
- Selenium IDE 教程
- Selenium - IDE 简介
- Selenium - 特性
- Selenium - 限制
- Selenium - 安装
- Selenium - 创建测试
- Selenium - 创建脚本
- Selenium - 控制流
- Selenium - 存储变量
- Selenium - 警报和弹出窗口
- Selenium - Selenese 命令
- Selenium - Actions 命令
- Selenium - Accessors 命令
- Selenium - Assertions 命令
- Selenium - Assert/Verify 方法
- Selenium - 定位策略
- Selenium - 脚本调试
- Selenium - 验证点
- Selenium - 模式匹配
- Selenium - JSON 数据文件
- Selenium - 浏览器执行
- Selenium - 用户扩展
- Selenium - 代码导出
- Selenium - 代码输出
- Selenium - JavaScript 函数
- Selenium - 插件
- Selenium WebDriver 教程
- Selenium - 简介
- Selenium WebDriver vs RC
- Selenium - 安装
- Selenium - 第一个测试脚本
- Selenium - 驱动程序会话
- Selenium - 浏览器选项
- Selenium - Chrome 选项
- Selenium - Edge 选项
- Selenium - Firefox 选项
- Selenium - Safari 选项
- Selenium - 双击
- Selenium - 右键点击
- Python 中的 HTML 报告
- 处理编辑框
- Selenium - 单个元素
- Selenium - 多个元素
- Selenium Web 元素
- Selenium - 文件上传
- Selenium - 定位器策略
- Selenium - 相对定位器
- Selenium - 查找器
- Selenium - 查找所有链接
- Selenium - 用户交互
- Selenium - WebElement 命令
- Selenium - 浏览器交互
- Selenium - 浏览器命令
- Selenium - 浏览器导航
- Selenium - 警报和弹出窗口
- Selenium - 处理表单
- Selenium - 窗口和标签页
- Selenium - 处理链接
- Selenium - 输入框
- Selenium - 单选按钮
- Selenium - 复选框
- Selenium - 下拉框
- Selenium - 处理 IFrame
- Selenium - 处理 Cookie
- Selenium - 日期时间选择器
- Selenium - 动态 Web 表格
- Selenium - Actions 类
- Selenium - Action 类
- Selenium - 键盘事件
- Selenium - 键上/下
- Selenium - 复制和粘贴
- Selenium - 处理特殊键
- Selenium - 鼠标事件
- Selenium - 拖放
- Selenium - 笔事件
- Selenium - 滚动操作
- Selenium - 等待策略
- Selenium - 显式/隐式等待
- Selenium - 支持特性
- Selenium - 多选
- Selenium - 等待支持
- Selenium - 选择支持
- Selenium - 颜色支持
- Selenium - ThreadGuard
- Selenium - 错误和日志记录
- Selenium - 异常处理
- Selenium - 其他
- Selenium - 处理 Ajax 调用
- Selenium - JSON 数据文件
- Selenium - CSV 数据文件
- Selenium - Excel 数据文件
- Selenium - 跨浏览器测试
- Selenium - 多浏览器测试
- Selenium - 多窗口测试
- Selenium - JavaScript 执行器
- Selenium - 无头执行
- Selenium - 捕获屏幕截图
- Selenium - 捕获视频
- Selenium - 页面对象模型
- Selenium - 页面工厂
- Selenium - 录制和回放
- Selenium - 框架
- Selenium - 浏览上下文
- Selenium - DevTools
- Selenium Grid 教程
- Selenium - 概述
- Selenium - 架构
- Selenium - 组件
- Selenium - 配置
- Selenium - 创建测试脚本
- Selenium - 测试执行
- Selenium - 端点
- Selenium - 自定义节点
- Selenium 报告工具
- Selenium - 报告工具
- Selenium - TestNG
- Selenium - JUnit
- Selenium - Allure
- Selenium 和其他技术
- Selenium - Java 教程
- Selenium - Python 教程
- Selenium - C# 教程
- Selenium - Javascript 教程
- Selenium - Kotlin 教程
- Selenium - Ruby 教程
- Selenium - Maven 和 Jenkins
- Selenium - 数据库测试
- Selenium - LogExpert 日志记录
- Selenium - Log4j 日志记录
- Selenium - Robot Framework
- Selenium - AutoIT
- Selenium - Flash 测试
- Selenium - Apache Ant
- Selenium - Github 教程
- Selenium - SoapUI
- Selenium - Cucumber
- Selenium - IntelliJ
- Selenium - XPath
Selenium WebDriver - 处理链接
Selenium Webdriver 可用于处理网页上的链接。在HTML术语中,每个链接(称为超链接)都由名为 anchor 的标签名标识。此外,网页上的每个链接都有一个名为 href 的属性。
HTML 中链接的标识
现在让我们讨论一下如何识别网页上显示的超链接的锚标签 - 下图所示。右键单击网页,然后单击 Chrome 浏览器中的“检查”按钮。之后,整个页面的相应 HTML 代码将可见。要检查页面上的“Created”链接,请单击下面突出显示的左上箭头。
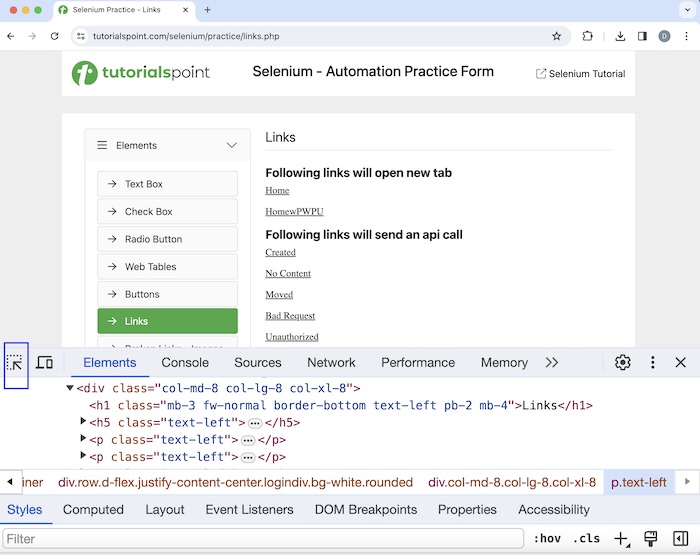
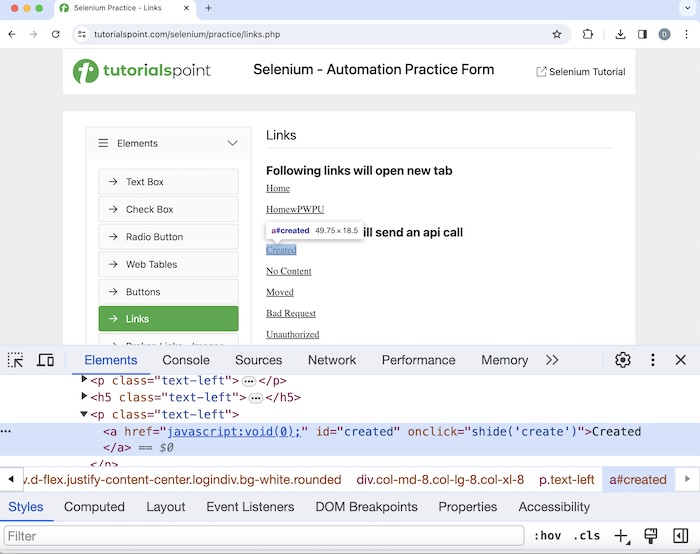
单击并指向“Created”超链接后,其 HTML 代码可见。
可以使用 Selenium 中的链接文本定位器来识别链接。将识别具有匹配链接文本值的第一个元素。
语法
Webdriver driver = new ChromeDriver();
driver.findElement(By.linkText("value of link text"));
使用链接文本定位器处理链接
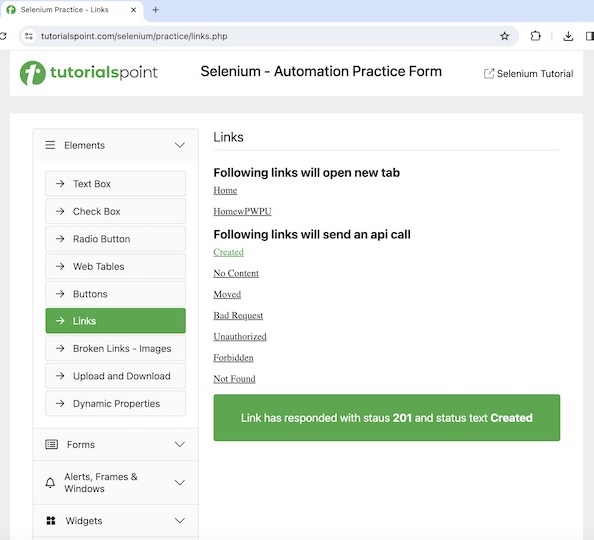
让我们以上面页面为例,单击“Created”链接后,页面上将显示文本Link has responded with status 201 and status text Created。
示例
package org.example;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.concurrent.TimeUnit;
public class HandLinks {
public static void main(String[] args) throws InterruptedException {
// Initiate the Webdriver
WebDriver driver = new ChromeDriver();
// adding implicit wait of 15 secs
driver.manage().timeouts().implicitlyWait(15, TimeUnit.SECONDS);
// Opening the webpage where we will identify an element
driver.get
("https://tutorialspoint.com/selenium/practice/links.php");
// identify link with link text locator then click
WebElement l = driver.findElement(By.linkText("Created"));
l.click();
// identify text locator
WebElement t = driver.findElement(By.xpath("/html/body/main/div/div/div[2]/div[1]"));
System.out.println("Text appeared is: " + t.getText());
// Closing browser
driver.quit();
}
}
输出
Text appeared is: Link has responded with status 201 and status text Created Process finished with exit code 0
在上面的示例中,单击链接Created后获得的带有消息的文本为Link has responded with status 201 and status text Created。
最后,收到消息Process finished with exit code 0,表示代码已成功执行。
使用部分链接文本定位器处理链接
可以使用 Selenium 中的部分链接文本定位器来识别链接。将识别具有匹配部分链接文本值的第一个元素。
语法
Webdriver driver = new ChromeDriver();
driver.findElement(By.partialLinkText("value of partial link text"));
示例
package org.example;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.concurrent.TimeUnit;
public class HandPartialLinks {
public static void main(String[] args) throws InterruptedException {
// Initiate the Webdriver
WebDriver driver = new ChromeDriver();
// adding implicit wait of 15 secs
driver.manage().timeouts().implicitlyWait(15, TimeUnit.SECONDS);
// Opening the webpage where we will identify an element
driver.get("https://tutorialspoint.com/selenium/practice/links.php");
// identify link with partial link text locator then click
WebElement l = driver.findElement(By.partialLinkText("Creat"));
l.click();
// identify text locator
WebElement t = driver.findElement(By.xpath("/html/body/main/div/div/div[2]/div[1]"));
System.out.println("Text appeared is: " + t.getText());
// Closing browser
driver.quit();
}
}
输出
Text appeared is: Link has responded with status 201 and status text Created
在上面的示例中,单击链接Created(使用部分链接文本)后获得的带有消息的文本为链接Link has responded with status 201 and status text Created。
使用标签名定位器处理链接
可以使用 Selenium 中的标签名定位器来识别链接。将识别具有匹配标签名值的第一个元素。
在上例中,我们单击并指向“Created”超链接后,其 HTML 代码可见,反映了锚标签名(称为“a”并用<>括起来)。
<a href="javascript:void(0);" id="created" onclick="shide('create')">Created</a>
语法
Webdriver driver = new ChromeDriver();
driver.findElement(By.tagName("a”));
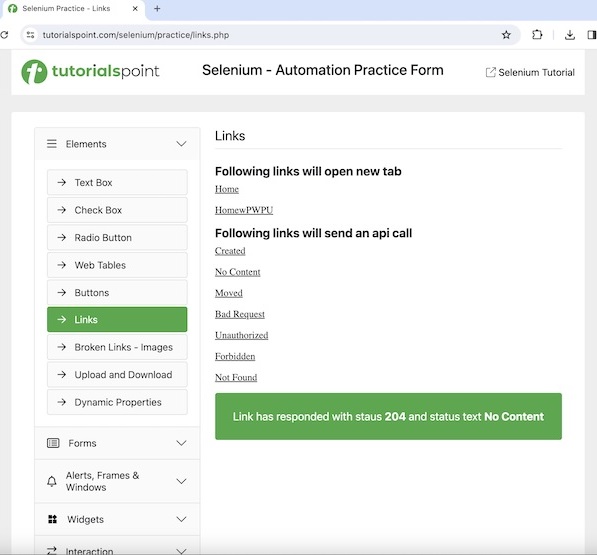
让我们以同一个页面为例,我们首先计算链接的总数,然后单击特定链接,例如“No Content”。单击该链接后,我们将获得文本Link has responded with status 204 and status text。
示例
package org.example;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.concurrent.TimeUnit;
import java.util.List;
public class TotalLinks {
public static void main(String[] args) throws InterruptedException {
// Initiate the Webdriver
WebDriver driver = new ChromeDriver();
// adding implicit wait of 15 secs
driver.manage().timeouts().implicitlyWait(15, TimeUnit.SECONDS);
// Opening the webpage where we will identify an element
driver.get("https://tutorialspoint.com/selenium/practice/links.php");
// identify link with link text locator then click
WebElement l = driver.findElement(By.linkText("No Content"));
l.click();
// Retrieve all links using locator By.tagName and storing in List
List<WebElement> totalLnks = driver.findElements(By.tagName("a") );
System.out.println( "Total number of links: " + totalLnks.size() ) ;
// Running loop through list of web elements
for( int j = 0; j < totalLnks.size(); j ++){
if( totalLnks.get(j).getText().equalsIgnoreCase("No Content") ) {
totalLnks.get(j).click();
WebElement t = driver.findElement(By.xpath("/html/body/main/div/div/div[2]/div[2]"));
// get the browser title to confirm navigation after click
System.out.println( "Get text after click: " + t.getText());
break ;
}
}
// Closing browser
driver.quit();
}
}
输出
Total number of links: 42 Get text after click: Link has responded with status 204 and status text No Content
在上面的示例中,我们计算了网页上链接的总数,并在控制台中收到了消息 - Total number of links: 42 和单击后获得的文本 Get text after click: Link has responded with status 204 and status text No Content。
结论
本教程总结了 Selenium Webdriver 处理链接的全面内容。我们首先介绍了如何在 HTML 中识别链接,并通过示例说明了如何使用 Selenium Webdriver 中的链接文本、部分链接文本和标签名定位器来处理链接。这使您掌握了 Selenium Webdriver 处理链接的深入知识。最好不断练习所学内容,并探索与 Selenium 相关的其他内容,以加深您的理解并拓宽视野。