
- Selenium 教程
- Selenium - 首页
- Selenium - 概述
- Selenium - 组件
- Selenium - 自动化测试
- Selenium - 环境搭建
- Selenium - 远程控制
- Selenium IDE 教程
- Selenium - IDE 简介
- Selenium - 特性
- Selenium - 限制
- Selenium - 安装
- Selenium - 创建测试
- Selenium - 创建脚本
- Selenium - 控制流
- Selenium - 存储变量
- Selenium - 警报和弹出窗口
- Selenium - Selenese 命令
- Selenium - Actions 命令
- Selenium - Accessors 命令
- Selenium - Assertions 命令
- Selenium - Assert/Verify 方法
- Selenium - 定位策略
- Selenium - 脚本调试
- Selenium - 验证点
- Selenium - 模式匹配
- Selenium - JSON 数据文件
- Selenium - 浏览器执行
- Selenium - 用户扩展
- Selenium - 代码导出
- Selenium - 代码输出
- Selenium - JavaScript 函数
- Selenium - 插件
- Selenium WebDriver 教程
- Selenium - 简介
- Selenium WebDriver vs RC
- Selenium - 安装
- Selenium - 第一个测试脚本
- Selenium - 驱动程序会话
- Selenium - 浏览器选项
- Selenium - Chrome 选项
- Selenium - Edge 选项
- Selenium - Firefox 选项
- Selenium - Safari 选项
- Selenium - 双击
- Selenium - 右击
- Python 中的 HTML 报告
- 处理编辑框
- Selenium - 单个元素
- Selenium - 多个元素
- Selenium Web 元素
- Selenium - 文件上传
- Selenium - 定位器策略
- Selenium - 相对定位器
- Selenium - 查找器
- Selenium - 查找所有链接
- Selenium - 用户交互
- Selenium - WebElement 命令
- Selenium - 浏览器交互
- Selenium - 浏览器命令
- Selenium - 浏览器导航
- Selenium - 警报和弹出窗口
- Selenium - 处理表单
- Selenium - 窗口和标签页
- Selenium - 处理链接
- Selenium - 输入框
- Selenium - 单选按钮
- Selenium - 复选框
- Selenium - 下拉框
- Selenium - 处理 IFrame
- Selenium - 处理 Cookie
- Selenium - 日期时间选择器
- Selenium - 动态 Web 表格
- Selenium - Actions 类
- Selenium - Action 类
- Selenium - 键盘事件
- Selenium - 键上/下
- Selenium - 复制和粘贴
- Selenium - 处理特殊键
- Selenium - 鼠标事件
- Selenium - 拖放
- Selenium - 笔事件
- Selenium - 滚动操作
- Selenium - 等待策略
- Selenium - 显式/隐式等待
- Selenium - 支持特性
- Selenium - 多选
- Selenium - 等待支持
- Selenium - 选择支持
- Selenium - 颜色支持
- Selenium - ThreadGuard
- Selenium - 错误和日志记录
- Selenium - 异常处理
- Selenium - 其他
- Selenium - 处理 Ajax 调用
- Selenium - JSON 数据文件
- Selenium - CSV 数据文件
- Selenium - Excel 数据文件
- Selenium - 跨浏览器测试
- Selenium - 多浏览器测试
- Selenium - 多窗口测试
- Selenium - JavaScript 执行器
- Selenium - 无头执行
- Selenium - 捕获屏幕截图
- Selenium - 捕获视频
- Selenium - 页面对象模型
- Selenium - 页面工厂
- Selenium - 记录和回放
- Selenium - 框架
- Selenium - 浏览上下文
- Selenium - DevTools
- Selenium Grid 教程
- Selenium - 概述
- Selenium - 架构
- Selenium - 组件
- Selenium - 配置
- Selenium - 创建测试脚本
- Selenium - 测试执行
- Selenium - 端点
- Selenium - 自定义节点
- Selenium 报告工具
- Selenium - 报告工具
- Selenium - TestNG
- Selenium - JUnit
- Selenium - Allure
- Selenium & 其他技术
- Selenium - Java 教程
- Selenium - Python 教程
- Selenium - C# 教程
- Selenium - Javascript 教程
- Selenium - Kotlin 教程
- Selenium - Ruby 教程
- Selenium - Maven 和 Jenkins
- Selenium - 数据库测试
- Selenium - LogExpert 日志记录
- Selenium - Log4j 日志记录
- Selenium - Robot Framework
- Selenium - AutoIT
- Selenium - Flash 测试
- Selenium - Apache Ant
- Selenium - Github 教程
- Selenium - SoapUI
- Selenium - Cucumber
- Selenium - IntelliJ
- Selenium - XPath
Selenium WebDriver - 识别多个元素
在本节中,我们将学习如何通过各种选项识别多个元素。让我们从了解如何通过 Id 识别多个元素开始。
通过 id
不建议通过定位器 id 来识别多个元素,因为 id 属性的值对于每个元素都是唯一的,并且适用于页面上的单个元素。
通过类名
导航到网页后,我们必须与页面上可用的 Web 元素进行交互,例如单击链接/按钮,在编辑框中输入文本等,以完成我们的自动化测试用例。
为此,我们的首要任务是识别这些元素。我们可以使用元素的 class 属性进行识别,并利用 find_elements_by_class_name 方法。通过此方法,所有具有匹配的 class 属性值的元素都将以列表的形式返回。
如果不存在具有匹配 class 属性值的元素,则将返回一个空列表。
通过类名识别多个元素的语法如下:
driver.find_elements_by_class_name("value of class attribute")
让我们看看具有 class 属性的 Web 元素的 html 代码,如下所示:

上图中突出显示的 class 属性值为 toc chapters。让我们尝试计算此类 Web 元素的数量。
代码实现
通过类名识别多个元素的代码实现如下:
from selenium import webdriver
driver = webdriver.Chrome(executable_path='../drivers/chromedriver')
#implicit wait time
driver.implicitly_wait(5)
#url launch
driver.get("https://tutorialspoint.com/about/about_careers.htm")
#identify elements with class attribute
l = driver.find_elements_by_class_name("chapters")
#count elements
s = len(l)
print('Count is:')
print(s)
#driver quit
driver.quit()
输出
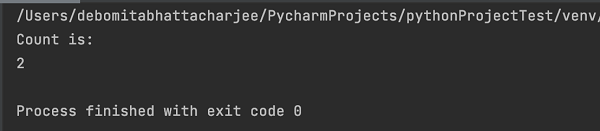
输出显示消息 - 进程退出代码为 0,这意味着上述 Python 代码成功执行。此外,控制台中还打印了具有 class 属性值 chapters(从 len 方法获取)的 Web 元素总数 - 2。
通过标签名
导航到网页后,我们必须与页面上可用的 Web 元素进行交互,例如单击链接/按钮,在编辑框中输入文本等,以完成我们的自动化测试用例。
为此,我们的首要任务是识别这些元素。我们可以使用元素的标签名进行识别,并利用 find_elements_by_tag_name 方法。通过此方法,所有具有匹配标签名的元素都将以列表的形式返回。
如果不存在具有匹配标签名的元素,则将返回一个空列表。
通过标签名识别多个元素的语法如下:
driver.find_elements_by_tag_name("value of tagname")
让我们看看一个 Web 元素的 html 代码,如下所示:
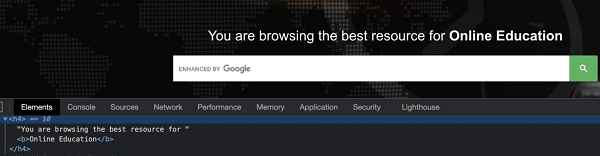
上图中突出显示的标签名为 h4。让我们尝试计算具有标签名 h4 的 Web 元素的数量。
代码实现
通过标签名识别多个元素的代码实现如下:
from selenium import webdriver
driver = webdriver.Chrome(executable_path='../drivers/chromedriver')
#implicit wait time
driver.implicitly_wait(5)
#url launch
driver.get("https://tutorialspoint.com/index.htm")
#identify elements with tagname
l = driver.find_elements_by_tag_name("h4")
#count elements
s = len(l)
print('Count is:')
print(s)
#driver quit
driver.quit()
输出
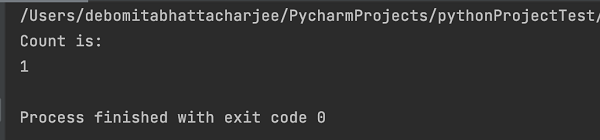
输出显示消息 - 进程退出代码为 0,这意味着上述 Python 代码成功执行。此外,控制台中还打印了具有标签名 h4(从 len 方法获取)的 Web 元素总数 - 1。
通过部分链接文本
导航到网页后,我们可能需要通过单击链接与 Web 元素进行交互以完成我们的自动化测试用例。部分链接文本用于具有锚标记的元素。
为此,我们的首要任务是识别这些元素。我们可以使用元素的部分链接文本属性进行识别,并利用 find_elements_by_partial_link_text 方法。通过此方法,所有具有匹配给定部分链接文本值的元素都将以列表的形式返回。
如果不存在具有匹配部分链接文本值的元素,则将返回一个空列表。
通过部分链接文本识别多个元素的语法如下:
driver.find_elements_by_partial_link_text("value of partial link text")
让我们看看链接的 html 代码,如下所示:
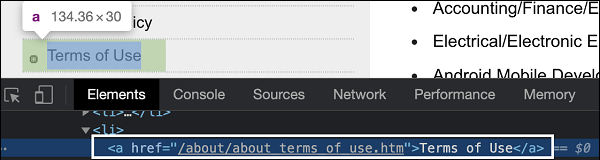
上图中突出显示的链接 - 使用条款的标签名为 a,部分链接文本为 - 条款。让我们尝试在识别后识别文本。
代码实现
通过部分链接文本识别多个元素的代码实现如下:
from selenium import webdriver
driver = webdriver.Chrome(executable_path='../drivers/chromedriver')
#implicit wait time
driver.implicitly_wait(5)
#url launch
driver.get("https://tutorialspoint.com/about/about_careers.htm")
#identify elements with partial link text
l = driver.find_elements_by_partial_link_text('Terms')
#count elements
s = len(l)
#iterate through list
for i in l:
#obtain text
t = i.text
print('Text is: ' + t)
#driver quit
driver.quit()
输出

输出显示消息 - 进程退出代码为 0,这意味着上述 Python 代码成功执行。此外,控制台中还打印了使用部分链接文本定位器(从 text 方法获取)识别的链接文本 - 使用条款。
通过链接文本
导航到网页后,我们可能需要通过单击链接与 Web 元素进行交互以完成我们的自动化测试用例。链接文本用于具有锚标记的元素。
为此,我们的首要任务是识别这些元素。我们可以使用元素的链接文本属性进行识别,并利用 find_elements_by_link_text 方法。通过此方法,所有具有匹配给定链接文本值的元素都将以列表的形式返回。
如果不存在具有匹配链接文本值的元素,则将返回一个空列表。
通过链接文本识别多个元素的语法如下:
driver.find_elements_by_link_text("value of link text")
让我们看看链接的 html 代码,如下所示:
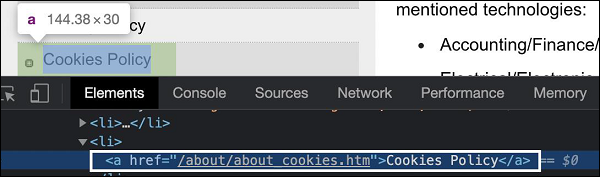
上图中突出显示的链接 - Cookie 策略的标签名为 a,链接文本为 - Cookie 策略。让我们尝试在识别后识别文本。
代码实现
通过链接文本识别多个元素的代码实现如下:
from selenium import webdriver
driver = webdriver.Chrome(executable_path='../drivers/chromedriver')
#implicit wait time
driver.implicitly_wait(5)
#url launch
driver.get("https://tutorialspoint.com/about/about_careers.htm")
#identify elements with link text
l = driver.find_elements_by_link_text('Cookies Policy')
#count elements
s = len(l)
#iterate through list
for i in l:
#obtain text
t = i.text
print('Text is: ' + t)
#driver quit
driver.quit()
输出

输出显示消息 - 进程退出代码为 0,这意味着上述 Python 代码成功执行。此外,控制台中还打印了使用链接文本定位器(从 text 方法获取)识别的链接文本 - Cookie 策略。
通过名称
导航到网页后,我们必须与页面上可用的 Web 元素进行交互,例如单击链接/按钮,在编辑框中输入文本等,以完成我们的自动化测试用例。
为此,我们的首要任务是识别这些元素。我们可以使用元素的 name 属性进行识别,并利用 find_elements_by_name 方法。通过此方法,将返回具有匹配 name 属性值的元素,并以列表的形式返回。
如果不存在具有匹配 name 属性值的元素,则将返回一个空列表。
通过名称识别多个元素的语法如下:
driver.find_elements_by_name("value of name attribute")
让我们看看一个 Web 元素的 html 代码,如下所示:
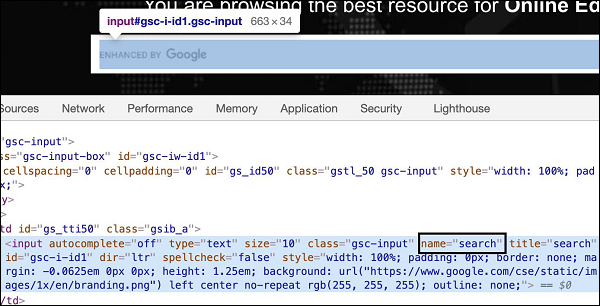
上图中高亮显示的编辑框有一个名为“search”的name属性。让我们尝试在识别它之后向此编辑框中输入一些文本。
代码实现
通过Name识别多个元素的代码实现如下:
from selenium import webdriver
driver = webdriver.Chrome(executable_path='../drivers/chromedriver')
#implicit wait time
driver.implicitly_wait(5)
#url launch
driver.get("https://tutorialspoint.com/index.htm")
#identify elements with name attribute
l = driver.find_elements_by_name('search')
#count elements
s = len(l)
#iterate through list
for i in l:
#obtain text
t = i.send_keys('Selenium Python')
v = i.get_attribute('value')
print('Value entered is: ' + v)
#driver quit
driver.quit()
输出

输出显示消息 - 进程退出代码为0,这意味着上述Python代码已成功执行。此外,在编辑框中输入的值(从get_attribute方法获取) - Selenium Python 会打印到控制台。
通过CSS选择器
导航到网页后,我们必须与页面上可用的 Web 元素进行交互,例如单击链接/按钮,在编辑框中输入文本等,以完成我们的自动化测试用例。
为此,我们的首要任务是识别元素。我们可以为它们的识别创建CSS选择器,并利用find_elements_by_css_selector方法。这样,具有给定CSS匹配值的元素将以列表的形式返回。
如果不存在具有CSS匹配值的元素,则将返回一个空列表。
语法通过CSS选择器识别多个元素如下:
driver.find_elements_by_css_selector("value of css")
CSS表达式规则
下面讨论了创建CSS表达式的规则:
- 要识别具有CSS的元素,表达式应为tagname[attribute='value']。我们还可以专门使用id属性来创建CSS表达式。
- 使用id,CSS表达式的格式应为tagname#id。例如,input#txt [此处input是标签名,txt是id属性的值]。
- 使用class,CSS表达式的格式应为tagname.class。例如,input.cls-txt [此处input是标签名,cls-txt是class属性的值]。
- 如果父元素有n个子元素,并且我们想识别第n个子元素,则CSS表达式应具有nth-of –type(n)。
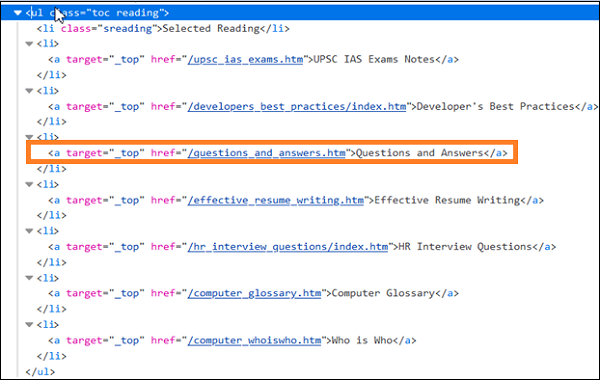
在上面的代码中,如果我们想识别ul[Questions and Answers]的第四个li子元素,则CSS表达式应为ul.reading li:nth-of-type(4)。类似地,要识别最后一个子元素,CSS表达式应为ul.reading li:last-child。
对于值动态变化的属性,我们可以使用^=来定位其属性值以特定文本开头的元素。例如,input[name^='qa'] [此处input是标签名,name属性的值以qa开头]。
对于值动态变化的属性,我们可以使用$=来定位其属性值以特定文本结尾的元素。例如,input[class$='txt'] 这里,input是标签名,class属性的值以txt结尾。
对于值动态变化的属性,我们可以使用*=来定位其属性值包含特定子文本的元素。例如,input[name*='nam'] 这里,input是标签名,name属性的值包含子文本nam。
让我们看看一个webelement的html代码:
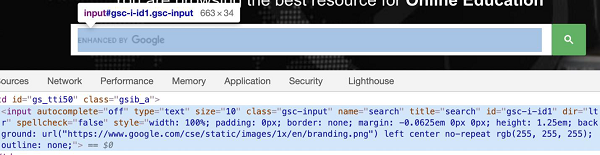
上图中高亮显示的编辑框有一个名为“search”的name属性,CSS表达式应为input[name='search']。让我们尝试在识别它之后向此编辑框中输入一些文本。
代码实现
通过CSS选择器识别多个元素的代码实现如下:
from selenium import webdriver
driver = webdriver.Chrome(executable_path='../drivers/chromedriver')
#implicit wait time
driver.implicitly_wait(5)
#url launch
driver.get("https://tutorialspoint.com/index.htm")
#identify elements with css
l = driver.find_elements_by_css_selector("input[name='search']")
#count elements
s = len(l)
#iterate through list
for i in l:
#obtain text
t = i.send_keys('Tutorialspoint')
v = i.get_attribute('value')
print('Value entered is: ' + v)
#driver quit
driver.quit()
输出

输出显示消息 - 进程退出代码为0,这意味着上述Python代码已成功执行。此外,在编辑框中输入的值(从get_attribute方法获取) - Tutorialspoint 会打印到控制台。
通过XPath
导航到网页后,我们必须与页面上可用的 Web 元素进行交互,例如单击链接/按钮,在编辑框中输入文本等,以完成我们的自动化测试用例。
为此,我们的首要任务是识别元素。我们可以为它们的识别创建XPath,并利用find_elements_by_xpath方法。这样,具有给定XPath匹配值的元素将以列表的形式返回。
如果不存在具有XPath匹配值的元素,则将返回一个空列表。
语法通过XPath识别多个元素如下:
driver.find_elements_by_xpath("value of xpath")
XPath表达式规则
下面讨论了创建XPath表达式的规则:
- 要识别具有XPath的元素,表达式应为//tagname[@attribute='value']。XPath可以分为两种类型:相对XPath和绝对XPath。绝对XPath以/符号开头,从根节点开始到我们要识别的元素。
例如:
/html/body/div[1]/div/div[1]/a
- 相对XPath以//符号开头,并且不从根节点开始。
例如:
//img[@alt='tutorialspoint']
让我们看看从根开始的高亮链接 - Home的html代码。
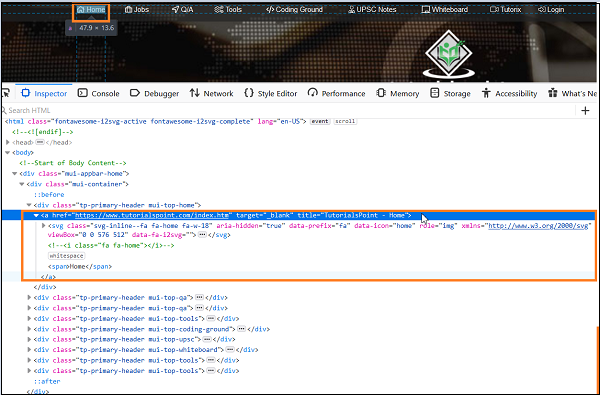
元素Home的绝对XPath可以如下所示:
/html/body/div[1]/div/div[1]/a.
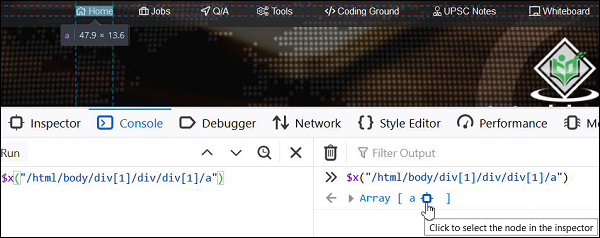
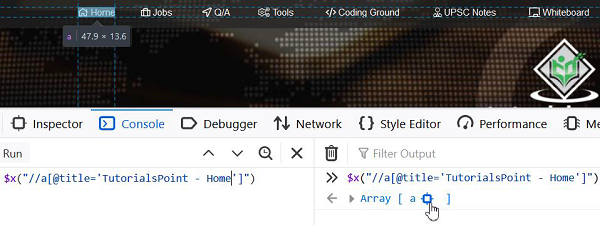
元素Home的相对XPath可以如下所示:
//a[@title='TutorialsPoint - Home'].
函数
还有一些可用的函数可以帮助构建相对XPath表达式:
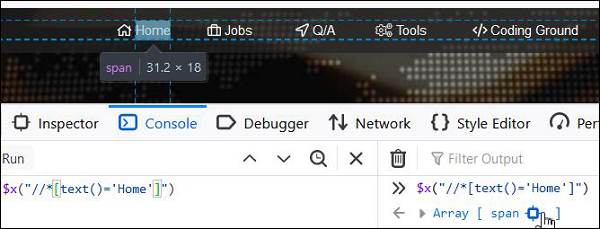
text()
它用于借助页面上的可见文本识别元素。XPath表达式如下:
//*[text()='Home'].
starts-with
它用于识别其属性值以特定文本开头的元素。此函数通常用于属性值在每次页面加载时都会更改的情况。
让我们看看元素Q/A的html:
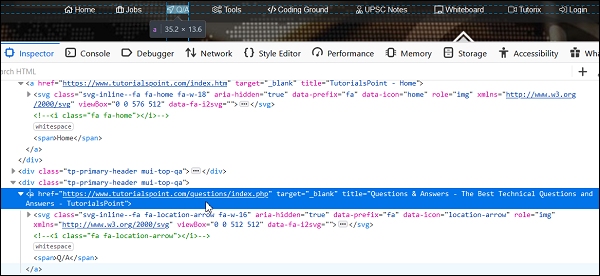
XPath表达式应如下所示:
//a[starts-with(@title, 'Questions &')].
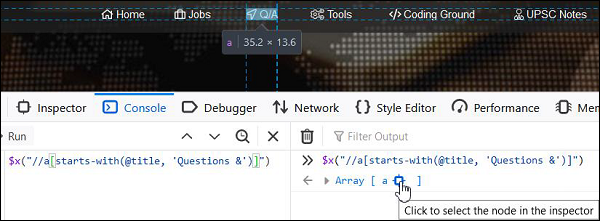
contains()
它识别其属性值包含子文本的元素。此函数通常用于属性值在每次页面加载时都会更改的情况。
XPath表达式如下:
//a[contains(@title, 'Questions & Answers')].
让我们看看一个webelement的html代码:
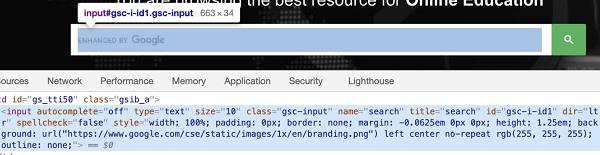
上图中高亮显示的编辑框有一个名为“search”的name属性,XPath表达式应为//input[@name='search']。让我们尝试在识别它之后向此编辑框中输入一些文本。
代码实现
通过XPath识别多个元素的代码实现如下:
from selenium import webdriver
driver = webdriver.Chrome(executable_path='../drivers/chromedriver')
#implicit wait time
driver.implicitly_wait(5)
#url launch
driver.get("https://tutorialspoint.com/index.htm")
#identify elements with xpath
l = driver.find_elements_by_xpath("//input[@name='search']")
#count elements
s = len(l)
#iterate through list
for i in l:
#obtain text
t = i.send_keys('Tutorialspoint - Selenium')
v = i.get_attribute('value')
print('Value entered is: ' + v)
#driver quit
driver.quit()
输出

输出显示消息 - 进程退出代码为0,这意味着上述Python代码已成功执行。此外,在编辑框中输入的值(从get_attribute方法获取) - Tutorialspoint - Selenium 会打印到控制台。